프로그래머라면 알아야 할 미래를 품은 7가지 언어, 브루스 테이트의 세븐 랭귀지 - 스칼라 챕터에 대한 정리입니다. 기본적인 스칼라 문법은 생략한 것이 많으니 읽는데 참고하시기 바랍니다. 프로그래밍 언어의 본질은 추상화라는 것을 알려주신 임백준 작가님께 감사드립니다.
1. 스칼라에 대하여
새로운 프로그래밍 패러다임은 언제나 하나의 언어가 아니라 여러 개의 언어와 함께 등장한다. 기존의 패러다임에 속한 언어들은 사용자들이 원래 패러다임 안에서 안전하게 살아가고 있는 동안 새로운 패러다임이 가지고 있는 개념을 조금씩 구현하며 상대방을 닮아간다. 예를 들어 에이다는 절차형 언어 내부에 캡슐화 같은 객체지향 아이디어를 구현했다.
1.1 자바와의 관련성
스칼라는 최소한 다리, 혹은 그 이상의 존재에 해당한다.
- 스칼라는 자바 가상 머신 위에서 동작한다. 따라서 스칼라는 이미 존재하는 코드와 나란히 실행될 수 있다.
- 스칼라는 자바 라이브러리 를 직접 사용할 수 있다. 따라서 개발자들은 이미 존재하는 프레임워크와 레거시 코드를 활용할 수 있다.
- 스칼라는 자바와 마찬가지로 정적 타이핑 을 사용한다. 따라서 두 언어는 철학적 기반을 공유한다.
- 스칼라의 문법은 자바와 가깝기 때문에 개발자들이 쉽게 배울 수 있다.
- 스칼라는 객체지향과 함수 프로그래밍 패러다임을 모두 지원 한다. 따라서 개발자들은 자신의 코드에 함수 프로그래밍 개념을 단계별로 조금씩 적용할 수 있다.
1.2 맹신은 없다
어떤 언어는 자기가 계승하는 언어를 너무 심하게 받아들인 나머지 기존의 언어를 더 이상 적합하지 않은 것으로 만드는 개념까지 받아들인다. 자바와의 유사성이 큼에도 불구하고, 스칼라의 설계는 자신만의 커뮤니티를 형성하기에 충분한 차별성을 갖는다.
| 자료형 유추 |
자바에서는 모든 변수, 인수, 매개변수에 대해서 자료형을 선언해야 한다. 스칼라는 가능한 모든 곳에서 변수의 자료형을 컴파일러가 유추한다.
| 함수 개념 |
스칼라는 자바 안에 중요한 함수 개념을 도입했다. 특히 스칼라는 이미 존재하는 함수를 다양한 방식으로 결합해서 새로운 함수를 만들 수 있도록 한다. 스칼라는 기초적인 문법적 설탕을 뿌리는 데서 멈추지 않는다.
| 불변 변수 |
자바도 불변 변수를 가질 수는 있지만, 흔히 사용되지 않는 수식어 키워드를 사용할 때에 한해서 그렇다. 스칼라가 우리로 하여금 변수가 불변인지 아니면 변경할 수 있는지 여부를 미리 결정하도록 강제하는 모습을 볼 수 있다. 이러한 결정은 동시성 문맥에서 애플리케이션이 동작하는 방식에 지대한 영향을 끼친다.
| 고급 프로그래밍 구조물 |
스칼라는 언어가 가진 기초 구성물을 잘 활용해서 그 위에 유용한 개념을 만들어 얹는다.
1.3 스칼라의 창시자 마틴 오더스키와의 인터뷰
브루스: 스칼라를 만든 이유가 무엇인가요?
오더스키 박사: 함수 프로그래밍 커뮤니티가 OOP에 대해서 갖는 다소 무시하는 듯한 태도와, 객체지향 진영이 함수 프로그래밍은 학술적 연구에 불과하다고 생각하는 것에 대해 좌절을 느끼곤 했습니다. 그래서 저는 두 개를 하나로 결합해서 뭔가 새롭고 강력한 것을 만들어낼 수 있다는 사실을 보여주고 싶었습니다.
브루스: 스칼라에서 가장 마음에 드는 부분은 어떤 것이지요?
오더스키 박사: 프로그래머가 원하는 내용을 자유롭게 표현할 수 있도록 하고, 가벼움을 느낄 수 있게 하고, 그와 동시에 자료형 시스템을 통해서 뭔가 강력한 기능을 지원할 수 있는 점을 만족스럽게 생각합니다.
브루스: 스칼라가 가장 잘 해결할 수 있는 문제는 어떤 것인가요?
오더스키 박사: 스칼라는 범용입니다. 스칼라가 다른 주류 언어에 비해서 갖는 특별한 장점은 함수 프로그래밍의 지원에 있습니다. 따라서 함수적인 접근이 의미를 갖는 곳이라면 어디에서든지 스칼라는 빛을 발합니다. 동시성이나 병렬처리, XML을 처리하는 웹 앱, 혹은 도메인 언어를 구현하는 경우 등이 그에 해당합니다.
브루스: 처음부터 다시 시작할 기회가 있다면 어떤 부분을 고치고 싶나요?
오더스키 박사: 스칼라의 지역 자료형 유추는 일반적으로 잘 동작하지만 약간의 한계까 있습니다. 처음부터 다시 시작할 수 있다면, 더 강력한 제약조건 해결기(constraint solver)를 사용할 것 같습니다.
트위터가 핵심 시스템을 개발하는 언어를 루비에서 스칼라로 바꾸었다. 객체지향적인 특징이 있기 때문에 자바로부터 전환하는 과정이 무척 부드럽기 떄문이기도 하지만, 스칼라가 주목을 받는 이유는 함수 프로그래밍 기능 때문이다. 순수한 함수 프로그래밍은 강력한 수학적 기초를 갖는 프로그래밍 스타일을 가능하게 만든다.
- 함수 프로그램은 함수로 이루어져 있다.
- 함수는 항상 어떤 값을 리턴한다.
- 동일한 입력이 주어지면 함수는 언제나 동일한 결과를 리턴한다.
- 함수 프로그램은 상태를 변경하거나 데이터를 변경하는 것을 피한다. 하나의 값을 설정했으면, 그 값을 끝까지 유지한다.
엄밀히 말해서 스칼라는, C++가 순수 객체지향 언어가 아닌 것처럼, 순수 함수 프로그래밍 언어가 아니다. 변경 가능한 값을 허용하기 때문에 어떤 함수가 동일한 입력에 대해서 전과 다른 출력을 하는 것이 가능하다. 하지만 스칼라는 함수 추상의 의미를 갖는 곳에서는 함수를 사용하는 것을 가능하게 한다.
1.4 함수 프로그래밍과 동시성
객체지향 언어를 사용하는 개발자들이 동시성과 관련해서 갖게 되는 가장 큰 문제는 변경 가능한 상태(mutable state), 즉 데이터의 값이 변할 수 있다는 사실이다. 초기 값이 설정된 이후에 또 다른 값을 가질 수 있는 변수를 변경 가능하다고 부른다. 동시성과 변경 가능한 상태의 관계는 오스틴 파워와 이블 박사의 관계에 해당한다. 두 개의 서로 다른 스레드가 동일한 데이터를 동시에 변경할 수 있다면, 그러한 연산이 해당 데이터를 정상적인 상태로 유지할 거라는 보장이 없고, 이런 연산을 테스트하는 것은 거의 불가능하다. 데이터베이스는 이 문제를 트랜잭션과 잠금장치(locking)를 이용해서 해결한다. 객체지향 프로그래밍 언어들은 이렇게 공유되는 데이터에 대한 접근을 통제하는 도구를 제공함으로써 문제를 해결한다. 하지만 대부분의 개발자는 심지어 그런 도구를 사용하는 방법을 알더라도 문제를 제대로 잘 해결하지 못한다.
함수 프로그래밍 언어들은 공식에서 변경 가능한 상태를 원천적으로 제거함으로써 문제를 해결한다. 스칼라는 변경 가능한 상태를 완전히 제거하도록 강제하지 않지만, 순수한 함수 스타일로 프로그래밍할 수 있는 도구를 제공한다.
2. 언덕 위의 성
<가위손>을 보면 약간 이상해 보이는 성이 언덕 위에 있다. 옛날에는 그 성이 신비하고 매혹적인 장소였지만 지금은 낡고 버려진 장소에 불과하다. 객체지향 패러다임도, 특히 초기에 구현된 내용은 이와 비슷하게 나이를 먹어가는 조짐을 보이고 있다. 초창기 정적 타이핑과 동시성을 구현했던 자바 언어는 이제 성형수술이 필요하다.
2.1 스칼라의 자료형
스칼라를 설치했으면 scala라는 명령을 콘솔에 입력하라.
scala> println("Hello, surreal world")
Hello, surreal world
scala> 1 + 1
res8: Int = 2
scala> (1).+(1)
res9: Int = 2
scala> 5 + 4 * 3
res10: Int = 17
scala> 5.+(4.*(3))
res11: Double = 17.0
scala> (5).+((4).*(3))
res12: Int = 17
보는 바와 같이 정수는 객체다. 자바를 사용할 때 나는 (원시 값인) int를 (객체인) Integer로 바꿀 때마다 머리를 쥐어뜯었다. 스칼라에서는 사실 미세한 예외를 제외하면 모든 것이 객체다. 그것만으로도 이미 정적 타이핑 시스템을 사용하는 대부분의 언어와 구별된다. 스칼라가 문자열을 어떻게 다루는지 보자.
scala> "abc".size
res13: Int = 3
스칼라에서는 문자열이 그 자체로 약간의 문법적 설탕이 가미된 일급 객체다. 이제 자료형이 서로 충돌하도록 만들어보자.
scala> 4 * "abc"
<console>:5: error: overloaded method value * with alternatives (Double)Double
...
스칼라는 사실 강한 타이핑 시스템을 사용하는 언어 인 것이다. 스칼라는 자료형 유추를 이용하기 때문에 대부분의 경우에는 문법적 단서를 이용해서 필요한 자료형을 스스로 파악한다. 하지만 루비와 달리 스칼라는 그러한 유추를 컴파일 시간에 수행한다. 스칼라 콘솔은 입력되는 코드의 내용을 실제로 한 줄씩 컴파일하고 그때마다 실행을 한다.
2.2 표현과 조건
scala> val a = 1
a: Int = 1
scala> val b = 2
b: Int = 2
scala> if (b < a) {
| println("true")
|} else {
| println("false")
|}
false
자료형을 선언하지 않았ㅇ므에 주목하라. 스칼라는 루비와 달리 자료형을 컴파일 시간에 바인딩한다. 하지만 자바와 달리 자료형을 유추할 수 있다. 따라서 필요하면 그렇게 할 수도 있지만 구태여 val a: Int = 1 과 같이 자료형을 지정하지 않아도 상관없다. 그리고 스칼라 변수인 val 키워드를 이용해서 시작되고 있음에 주목하라. var 키워드를 사용할 수도 있다. val은 불변 값을 의미하고 var은 변경 가능한 값을 의미한다.
scala> Nil
res3: Nil.type = List()
scala> if (Nil) println("true")
<console>:5: error: type mismatch;
found : Nil.type
required: Boolean
Nil은 비어 있는 리스트이며, 따라서 Nil이나 0을 불리언 값처럼 검사할 수 없다. 이런 동작은 스칼라가 가진 강한 정적 타이핑 철학과 일치한다.
2.3 루프
정적 타이핑을 둘러싼 나의 내적 갈등
초보자들은 프로그래밍 언어에서 강한 타이핑과 정적 타이핑을 혼동한다. 거칠게 말해서 강한 타이핑이란 언어가 두 개의 자료형이 서로 호환되는지 여부를 검사하고, 만약 호환되지 않으면 에러를 발생시키거나 강제로 자료형을 반환함을 뜻한다. 겉으로 보기에 자바와 루비는 모두 강한 타이핑을 사용한다. 이에 비해 어셈블리와 C 컴파일러는 약한 타이핑을 사용한다. 컴파일러가 메모리 안에 저장되어 있는 데이터가 정수인지, 문자열인지, 그냥 임의의 데이터인지 신경 쓰지 않는다는 의미다.
정적인가 동적인가 하는 것은 완전히 다른 문제다. 정적 타이핑 언어는 자료형 구조에 기초해서 다형성을 적용시킨다. (정적인) 유전적 청사진에 의거해서 오리인가, 아니면 그저 오리처럼 꽥꽥거리며 걷기 때문에 오리인가? 정적 타이핑을 사용하는 언어는 컴파일러와 도구가 코드에 담긴 에러를 검출하고, 코드의 키워드를 색상을 이용해서 강조하고, 리팩토링 기능을 제공하는 등의 이점을 누릴 수 있다. 그에 비해 코딩할 때 조금 더 수고를 해야 하고 제한도 뒤따른다. 정적 타이핑에서 오는 이러한 트레이드오프에 대해 어떤 생각을 하는가에 따라서 개발자로서의 역사가 달라질 것이다.
내가 처음 객체지향 개발에 사용한 언어는 자바였다. 자바의 정적 타이핑 울타리에서 벗어나기 전까지 나는 꼬리를 물며 나타나는 프레임워크를 만났었다. 우리는 당시 자바의 타이핑 모델을 더 동적으로 만들기 위해서 애썼고, 이러한 전투의 고비마다 자바가 우리를 위한 프로그래밍 환경이라기보다 오히려 적군이라고 느낄 수 밖에 없었다. 그리하여 내가 저술한 책들도 동적인 프레임워크라는 주제에서 출발해서 나중에는 동적인 언어 자체를 향해 나아갔다.
따라서 내가 정적 타이핑 언어에 대해서 가지고 있는 일종의 편견은 자바와의 전쟁에서 비롯되었다. 하스켈이 가지고 있는 탁월한 정적 타이핑 시스템은 이러한 상처로부터 서서히 벗어나는 계기가 되었다.
for 루프는 자바나 C에서와 거의 똑같지만 약간의 문법적 차이가 있다.
// scala/for_loop.scala
def forLoop {
println("for loop using Java-style iteration")
for (i <- 0 until args.length) {
println(args(i))
}
}
인수는 <- 연산자 앞에 있는 변수다. 그 뒤로 '초기 값 until 마지막 값'이라는 형태를 갖는 범위가 온다. 이 경우 우리는 명령줄에서 전달된 인수를 이용해서 순차 방문을 수행한다.
$ scala code/scala/for_loop.scala its all in the grind
for loop using Java-style iteration
its
all
in
the
grind
2.4 범위와 튜플
스칼라는 루비처럼 언어 자체가 범위(range)를 지원한다.
scala> val range = 0 until 10
range: Range = Range(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> range.start
res2: Int = 0
scala> range.end
res3: Int = 10
스칼라는 프롤로그처럼 튜플을 제공한다. 튜플은 길이가 고정된 객체 집합이다. 이와 같은 패턴을 다른 함수 언어에서도 발견할 수 있다. 튜플에 저장된 객체는 서로 자료형이 달라도 상관없다. 순수 함수 언어에서는 개발자들이 객체와 속성을 종종 튜플을 이용해서 표현한다.
scala> val person = ("Elvis", "Presley")
person: (java.lang.String, java.lang.String) = (Elvis, Presley)
scala> person._1
res9: java.lang.String = Elvis
scala> person._2
res10: java.lang.String = Presley
스칼라는 여러 개의 값을 한꺼번에 할당하는 연산을 수행할 때 리스트가 아니라 튜플을 사용한다. 튜플은 고정된 길이를 갖기 때문에 스칼라는 튜플에 저장된 값을 이용해서 정적 타이핑 검사를 수행할 수 있다.
scala> val (x, y) = (1, 2)
x: Int = 1
y: Int = 2
scala> val (a, b) = (1, 2, 3)
<console>:15: error: constructor cannot be instantiated to expected type;
...
2.5 스칼라에서의 클래스
속성을 가지고 있지만 메서드나 생성자를 갖지 않는 단순한 클래스는 스칼라에서 한 줄로 정의할 수 있다.
class Person(firstName: String, lastName: String)
2.6 클래스를 확장하기
짝 객체와 클래스 메서드
자바와 루비에서는 클래스 메서드와 인스턴스 메서드를 하나의 클래스 안에서 만들 수 있다. 자바에서 클래스 메서드는 static 키워드를 표시한다. 루비는 def self.class_method 를 이용한다. 스칼라는 이런 방법을 사용하지 않는다. 대신 인스턴스 메서드는 class 정의 내부에서 선언한다. 만약 그것이 하나의 객체 인스턴스만 갖는다면 class 키워드 대신 object 키워드를 이용해서 정의한다.
object TrueRing {
def rule = println("To rule them all")
}
TrueRing.rule
TrueRing의 내용은 보통의 class 정의와 완전히 동일하지만, 추가적으로 싱글턴 객체를 생성한다. 스칼라에서는 객체가 object 정의와 class 정의를 모두 가질 수 있다. 이러한 방법을 사용하면 클래스 메서드는 싱글턴 객체 선언 내에서, 인스턴스 메서드는 클래스 선언 내에서 생성할 수 있다. 이 예에서는 rule이라는 이름의 메서드가 클래스 메서드다. 이렇게 class와 object를 같이 사용하는 방법을 짝 객체(companion object)라고 부른다.
트레이트
모든 객체지향 언어는 하나의 객체가 여러 개의 역할을 담당할 수 있어야 한다. 하나의 객체는 영원히 나열할 수 있는 나무를 품은 관목 숲과 같다. 이러한 숲이 바이너리 데이터를 어떻게 MySQL에 집어넣는지 일일이 알아야 하는 상황은 바람직하지 않다. C++는 다중 상속을 이용하고, 자바는 인터페이스를 이용하고, 루비는 믹스인을 이용하고, 스칼라는 트레이트를 이용한다. 스칼라의 트레이트는 모듈을 이용해서 구현된 루비의 믹스인과 비슷하다. 혹은 자바의 인터페이스에 구현 코드를 추가한 것이라고 생각해도 좋다. 트레이트를 구체적인 내용이 부분적으로 구현된 클래스라고 생각할 수도 있다. 트레이트는 하나의 중요한 관심사항을 구현하는 것으로 국한되는 것이 이상적이다.
class Person(val name: String)
trait Nice
def greet() = println("Howdily doodily.")
class Character(override val name: String) extends Person(name) with Nice
val flanders = new Character("Ned")
flanders.greet
3. 정원 손질하기와 그 밖의 트릭
<가위손>에는 마법 같은 순간이 있다. 언덕 위의 저택을 떠난 에드워드가 비범한 능력으로 인간 사회에서 특별한 위치를 가질 수 있다는 사실을 깨달을 때다.
사람들은 기존의 절차형 프로그래밍을 계속 수행하면서 동시에 객체지향 개념을 실험해볼 수 있는 언어가 필요했다. C++가 등장했을 떄 사람들은 새로운 객체지향 트릭을 시도해보면서 이미 익숙한 C의 절차적 기능을 지속시킬 수 있었다. 그 결과 사람들은 마침내 낡은 문백 안에서 새로운 트릭을 사용하기 시작했다.
3.1 var 대 val
스칼라에서는 val이 불변을 의미하고 var는 값이 변할 수 있음을 뜻한다.
어떤 면에서 스칼라는 전통적인 명령형 프로그래밍 스타일을 지원하기 위해서 var로 지정되는 변수를 도입했는데, 스칼라를 배우는 동안에는 더 나은 동시성 지원을 위해서 var를 가급적 피하는 것이 최선이다. 바로 이와 같은 기본적인 설계 철학이 함수 프로그래밍을 객체지향 프로그래밍으로부터 구별해주는 핵심적인 요소에 해당한다. 변경 가능한 상태는 동시성을 제한한다.
3.2 컬렉션
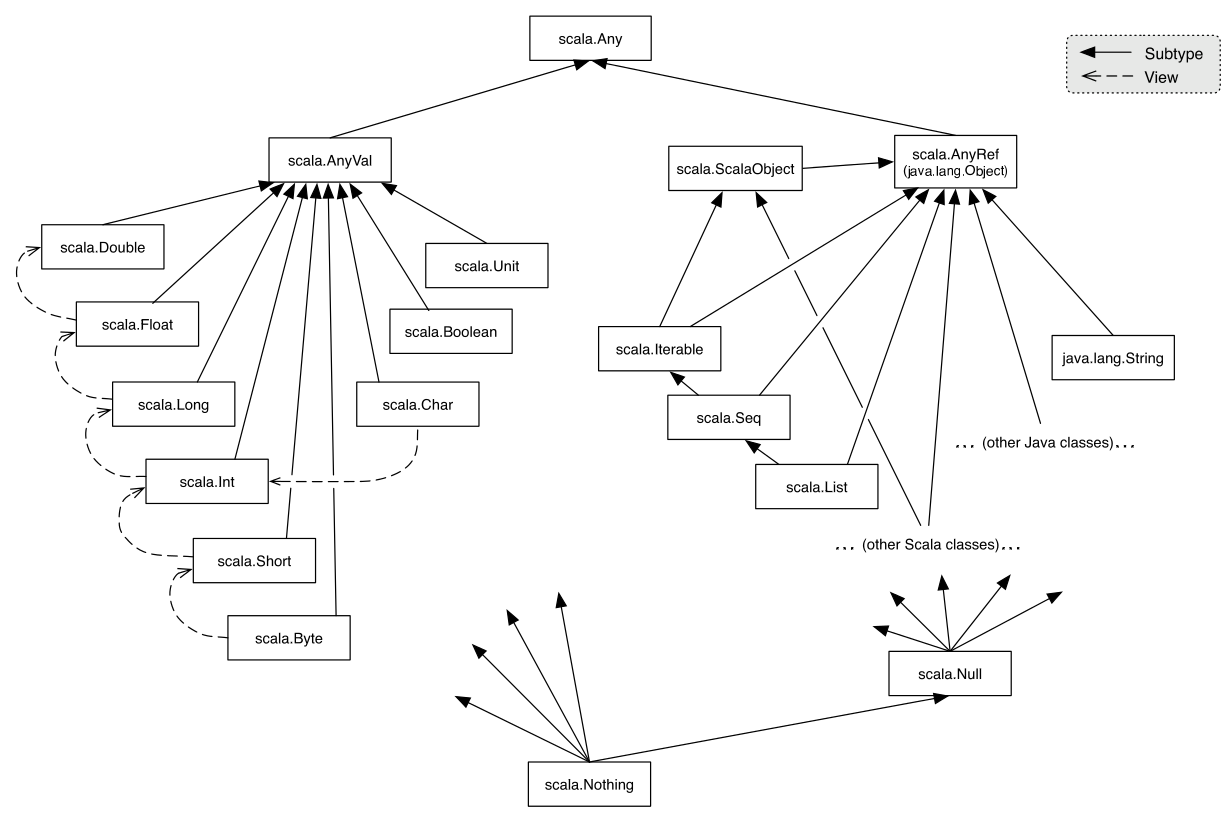
Any와 Nothing
익명 함수를 살펴보기 전에 스칼라가 가지고 있는 클래스 계층구조에 대해서 짚고 넘어가자. 스칼라를 자바와 함께 사용하는 경우에는 자바의 클래스 계층구조에 대해서 더 많이 신경을 쓰게 될 것이다. 그렇지만 스칼라의 자료형에 대해서도 약간 알 필요가 있다. Any는 스칼라의 클래스 계층구조에서 가장 상위에 존재하는 뿌리 클래스다. 조금 헷갈리는 내용이기는 하지만, 스칼라의 자료형은 모두 Any를 상속한다는 점을 기억하라.
마찬가지로 Nothing은 모든 자료형의 하위 자료형이다. 이를 통해 함수는, 예컨대 컬렉션에서 Nothing을 리턴하는 식으로 주어진 함수를 위한 리턴 값에 순응할 수 있다. 모든 것은 Any를 상속하고 Nothing은 모든 것을 상속한다.

nil 개념을 다룰 때는 몇 가지 다른 뉘앙스가 존재한다. Null은 Trait이고, null은 Null 자료형의 인스턴스로 자바의 null과 비슷하다. 즉, 텅 빈 값이라는 뜻이다. 속이 빈 컬렉션은 Nil이다. 이와 반대로 Nothing은 모든 것의 하위자료형에 해당하는 트레이트다. Nothing은 인스턴스가 없기 때문에 그에 대한 참조를 Null처럼 제거(derefence)할 수 없다. 예를 들어 Exception을 발생시키는 메서드는 리턴 자료형이 아무 값도 존재하지 않음을 의미하는 Nothing이다.
3.3 컬렉션과 함수
강력한 함수 패러다임 기초를 사용하는 언어가 가지고 있는 개념 몇 가지 중 첫 번째는 고계함수다. 일상적인 언어로 표현하자면 고계함수란 다른 함수를 생산하거나 소비하는 함수를 의미한다. 더 엄밀하게 말하면 고계함수는 다른 함수를 입력 매개변수로 받아들이거나 다른 함수를 리턴하는 함수다. 다른 함수를 사용하는 함수를 활용하는 것은 함수 프로그래밍 언어 패밀리에서 결정적으로 중요한 의미를 가지며, 다른 종류의 언어를 사용할 때조차 건설적인 영향을 미친다.
스칼라는 고계함수를 강력하게 지원한다. 함수를 취해서 다른 변수나 매개변수에 할당하는 것도 가능하다. 함수를 함수에 집어넣을 수도 있고 함수가 함수를 리턴하게 할 수도 있다.
4. 털 다듬기
<가위손>에서 스토리가 절정으로 치닫기 직전에, 에드워드는 자신의 가위를 이용해 일상적인 예술을 수행하는 법을 터득한다. 나무를 손질해서 공룡을 만들고, 비달 사순 같은 기술을 발휘해서 환상적인 머리를 만들어내고, 요리를 손질하기까지 한다. 스칼라를 이용하다 보면 가끔 곤혹스러운 순간이 있기는 하지만, 스칼라가 손에 제대로 맞는다는 느낌이 들 때는 그것이 할 수 있는 일의 경계가 무한히 확장된다. XML이나 동시성처럼 어려운 작업이 거의 평범한 일처럼 느껴질 정도다.
1. XML
스칼라는 XML의 지위를 격상해 아예 언어 내부의 구조물로 포함하는 전략을 취했다. 그래서 XML을 마치 문자열처럼 쉽게 표현할 수 있다.
scala> val movies =
| <movies>
| <movie genre="action">Pirates of the Caribbean</movie>
| <movie genre="fairytale">Edward Scissorhands</movie>
| </movies>
scala> movies.text
res1: String =
Pirates of the Caribbean
Edward Scissorhands
scala> val movieNodes = movies \ "movie"
movieNodes: scala.xml.NodeSeq =
<movie genre="action">Pirates of the Caribbean</movie>
<movie genre="fairytale">Edward Scissorhands</movie>
2. 패턴 매칭
패턴 매칭은 데이터의 일부분을 이용해서 코드를 조건적으로 실행하는 것이다. 스칼라는 XML을 해석하거나 스레드 사이에서 메시지를 전달하는 등의 경우에 패턴 매칭을 자주 사용한다.
def doChore(chore: String): String = chore match {
case "clean dishes" => "scrub, dry"
case "cook dinner" => "chop, sizzle"
case _ => "whine, complain"
}
3. 동시성
스칼라의 가장 중요한 의미의 하나는 그것이 동시성을 다루는 방식에 있다. 주요한 구조물은 액터(actor)와 메시지 전달이다. 액터는 스레드 풀과 큐를 가지고 있다. 어떤 액터에 (! 연산자를 이용해서) 메시지를 전달하면, 해당 액터의 큐에 객체가 저장된다. 액터는 큐에 메시지를 읽어서 필요한 동작을 수행한다. 액터는 종종 패턴 매칭을 이용해서 메시지를 감지하고 적절한 동작을 수행한다.
5. 스칼라를 마무리하며
스칼라는 두 개의 프로그래밍 패러다임을 지원한다. 객체지향 기능으로 스칼라는 자바의 대안으로 굳건히 자리매김했다. 루비나 Io와 달리 스칼라는 정적 타이핑 전략을 사용한다. 문법적으로 보았을 때 스칼라는 자바로부터 중괄호, 생성자 등 많은 것을 가져왔다.
스칼라는 또한 함수 개념과 불변 변수 등을 강력하게 지원한다. 스칼라는 동시성과 XML에 강하게 초점을 맞추고 있기 때문에 현재 자바로 개발되어 있는 다양한 엔터프라이즈 애플리케이션을 개발하는 데 적합하다.
스칼라의 함수 패러다임 능력은 이 책에서 소개한 수준을 훨씬 뛰어넘는다. 커링, 완전한 클로저, 다중 매개변수 리스트, 혹은 예외 처리와 같은 구조물은 다루지 않았다. 하지만 이러한 기능들은 스칼라에게 강력함과 유연함을 제공하는 가치있는 개념들이다.
5.1 핵심 강점
스칼라의 장점은 대부분 자바 환경과 잘 통합된다는 사실과 잘 설계된 기능을 중심으로 존재한다. 특히 액터, 패턴 매칭, XML의 통합은 매우 중요하며 훌륭하게 설계되어 있다.
동시성
스칼라의 동시성을 다루는 방식은 동시성 프로그래밍에서 이루어지고 있는 주요한 발전을 반영한다. 액터 모델과 스레드 풀은 환영할 만한 발전이며, 변경 가능한 상태를 배제한 상태에서 애플리케이션을 만들 수 있도록 한 부분은 엄청난 발전이다.
동시성 모델은 전체 스토리의 일부일 뿐이다. 객체들이 상태를 공유하는 경우에는 최선을 다해서 불변하는 값을 이용하도록 노력해야 한다. Io와 스칼라는 변경 가능한 상태를 허용하지만 불변성을 지원하는 라이브러리와 키워드를 제공함으로써 이 부분과 관련해서 성공을 거두었다. 불변성은 동시성과 관련해서 코드의 설계를 향상시키고자 할 때 사용할 수 있는 가장 중요한 기법이다.
낡은 자바의 진화
스칼라는 이미 존재하는 강력한 사용자 기반에서 출발한다. 바로 자바 커뮤니티다. 스칼라 애플리케이션은 자바 라이브러리를 직접 사용할 수 있고, 필요하면 프록시 객체 코드를 생성함으로써 그렇게 할 수도 있다. 스칼라와 자바의 호환성(interoperability)은 탁월하다. 자료형을 유추하는 기능은 자바의 낡은 타이핑 시스템과 비교하면 절실하게 요구되었던 개선이다.
스칼라는 자바 커뮤니티에 새로운 기능을 제공하기도 한다. 코드 블록은 언어가 지원하는 기능의 일부이며, 핵심적인 컬렉션 라이브러리에서 잘 활용된다. 스칼라는 또한 트레이트라는 형태로 믹스인 기능을 지원하기도 한다. 패턴 매칭도 상당한 수준의 개선이다. 이러한 기능과 다른 기능을 활용하면 자바 개발자는 수준 높은 함수 패러다임을 공부하지 않으면서도 수준 높은 프로그래밍 언어를 손에 넣을 수 있다.
DSL
루비에서와 마찬가지로 스칼라의 연산자는 메서드와 다르지 않으며, 따라서 대개의 경우 그들을 오버라이드할 수 있다는 사실을 기억하라.
XML
스칼라는 내부적으로 통합된 XML 기능을 지원한다. 패턴 매칭은 여러 가지 형태의 XML 구조를 쉽게 해석할 수 있도록 한다. 복잡한 XML을 읽어 들일 수 있도록 해주는 XPath 문법의 지원은 단순하고 읽기 쉬운 코드를 가능하게 한다.
다리 놓기
새로운 프로그래밍 패러다임이 등장할 때마다 그들은 일종의 다리를 필요로 한다. 스칼라는 이러한 다리의 기능을 수행하기에 매우 적합하다. 함수 프로그래밍 모델은 동시성을 잘 지원하기 때문에 중요한 의미를 갖는다. 특히 요즘에는 프로세서가 점점 더 동시성을 추구하는 방향으로 진화하고 있다. 스칼라는 개발자가 함수 패러다임에 점진적으로 다가서는 것을 쉽게 만들어준다.
5.1 약점
문법적인 측면에서 어렵고 학술적이라고 생각한다. 문법이라는 것이 취향에 좌우되는 측면이 많기는 하지만, 스칼라는 다른 언어에 비해서 특히 나이 많은 개발자들의 눈에는 어려운 부분이 많다는 점이 사실이다.
정적 타이핑
정적 타이핑은 함수 프로그래밍 언어에서 자연스럽지만, 객체지향용 자바 스타일 정적 타이핑 시스템은 문제가 있다. 경우에 따라 컴파일러가 요구하는 내용을 만족시키기 위해 개발자에게 짐을 씌워야 하는 경우가 있다. 정적 타이핑을 사용하면 그러한 짐의 무게가 생각보다 무거울 때가 있다. 이것이 코드, 문법, 프로그램 설계에 미치는 영향은 크다. 트레이트는 이러한 짐의 무게를 조금 덜어주었지만 개발자를 위한 유연성과 컴파일 시간에 요구되는 검사 사이에는 확실히 어떤 트레이드오프가 존재한다는 사실을 깨달았다.
변경 가능성
다리 역할을 하는 언어를 만들 때는 일종의 타협을 생각해야 한다. 스칼라가 수행한 중요한 타협의 하나는 변경 가능성을 허용하는 것이었다. var라는 이름의 키워드를 이용해서 스칼라는 판도라의 상자를 열었다. 변경 가능한 상태는 동시성과 관련해서 여러 가지 종류의 버그를 낳기 때문이다.
{kind=link}